Mein AI-Agent baut schneller als ich reviewen kann. Was jetzt?
AI-Agents generieren Features in Minuten, Review dauert Stunden. Wie du den Bottleneck löst: automatische Verification statt manueller Code-Review.
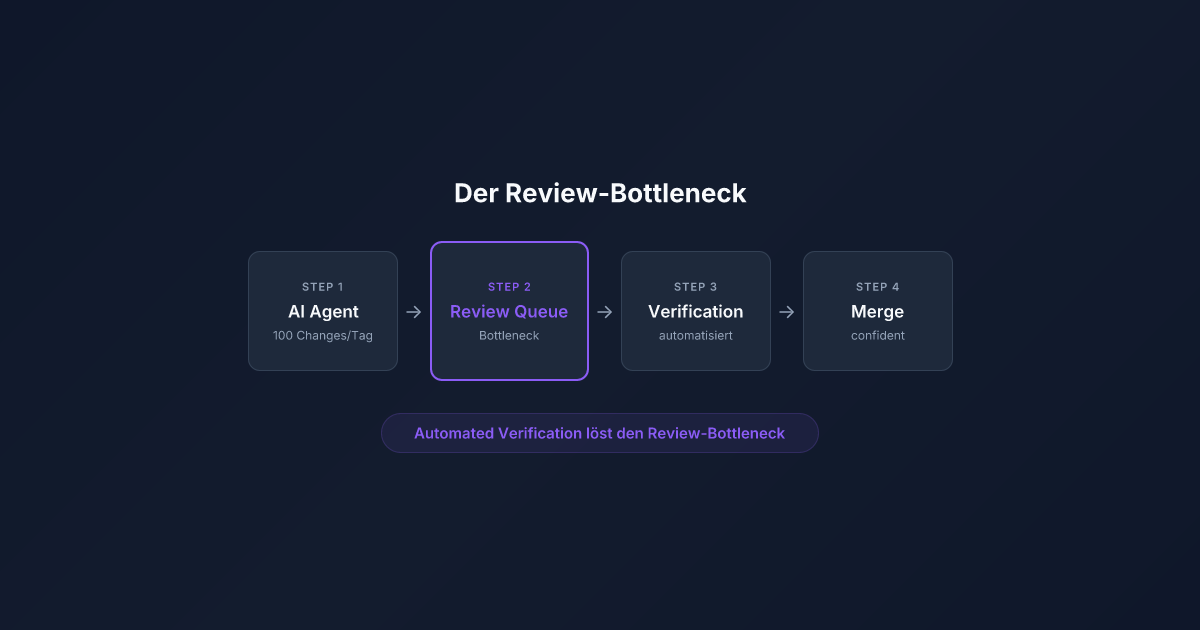
Wenn dein AI-Agent Features in Minuten generiert, aber dein Review Stunden dauert, bist du zum Bottleneck geworden. Die Lösung: Automatisiere die Verification, nicht den Review. Lass den Agent seinen eigenen Output verifizieren — du reviewst nur noch Architekturentscheidungen und Verdicts statt jede Zeile Code.
Dieser Artikel zeigt, wie du den Shift von manuellem Code-Review zu automatischer Behavior-Verification machst — ohne an Qualität zu verlieren.
Warum bin ich plötzlich der Bottleneck?
Weil AI die Development-Geschwindigkeit um den Faktor 5 bis 10 beschleunigt hat, aber die Verification-Geschwindigkeit unverändert menschlich limitiert ist.
Vor AI-Agents: Du schreibst ein Feature in 4 Stunden, reviewst es in 30 Minuten. Verhältnis 8:1 — Review ist kein Engpass.
Mit AI-Agents: Der Agent schreibt dasselbe Feature in 15 Minuten. Dein Review dauert weiterhin 30 bis 90 Minuten — weil du Code lesen musst, den du nicht selbst geschrieben hast. Verhältnis 1:2 bis 1:6 — Review dauert jetzt länger als Development.
Die Asymmetrie im Detail:
- Agent generiert 5 Features pro Tag — Jedes mit 3 bis 10 geänderten Dateien, 200 bis 500 Zeilen Diff. Das sind 1.000 bis 5.000 Zeilen Code pro Tag, die reviewed werden wollen.
- Du reviewst mit menschlicher Geschwindigkeit — Studien zeigen: effektives Code-Review schafft 200 bis 400 Zeilen pro Stunde. Bei 2.000 Zeilen Agent-Output brauchst du 5 bis 10 Stunden Review — für einen Tag Arbeit.
- Review-Qualität sinkt mit Volumen — Nach 60 bis 90 Minuten konzentriertem Review fällt die Defect-Detection-Rate drastisch. Bei 5 Stunden Review findest du die Bugs in Stunde 4 und 5 nicht mehr.
Das Ergebnis: Entweder du reviewst gründlich und wirst zum Engpass, oder du reviewst oberflächlich und lässt Fehler durch. Beides ist keine Lösung.
Was genau dauert beim Review so lange?
Nicht das Lesen der Diff — sondern das mentale Kompilieren von Code, den jemand anderes (oder etwas anderes) geschrieben hat.
Die tatsächlichen Zeitfresser:
- Mental Compilation — Du liest
Hero.tsxund musst im Kopf nachvollziehen: Was passiert wenn der User klickt? Welchen State ändert das? Welche anderen Komponenten sind betroffen? Bei eigenem Code weißt du das intuitiv. Bei Agent-Code musst du es rekonstruieren. - Cross-File-Nachverfolgung — Der Agent hat 7 Dateien geändert. Du musst verstehen, wie die Änderungen zusammenhängen. Hat die Änderung in
router.tsAuswirkungen aufCheckout.tsx? Das erfordert aktives Navigieren durch die Codebase. - Edge-Case-Denken — „Was passiert bei leerem Warenkorb? Bei ungültiger E-Mail? Bei Timeout?" Der Agent hat möglicherweise nicht alle Edge Cases bedacht. Du musst sie mental durchspielen — für jede geänderte Funktion.
- Manuelles Durchklicken — Du wechselst zum Browser, öffnest die App, klickst den Flow durch: Login → Dashboard → Feature → zurück. Bei 5 Features pro Tag: 5 manuelle Durchklick-Sessions.
- Kontext-Aufbau — Jedes Mal wenn du zwischen zwei Agent-Outputs wechselst, musst du den Kontext neu aufbauen: Was war der Task? Was hat der Agent geändert? Was war der erwartete Zustand vorher?
Die Summe dieser Aufwände erklärt, warum 15 Minuten Agent-Arbeit zu 60 bis 90 Minuten Review werden. Das Problem ist nicht, dass du zu langsam bist — es ist, dass Review eine fundamentally sequential menschliche Tätigkeit ist.
Kann ich einfach weniger reviewen?
Ja — aber strategisch, nicht nachlässig. Der Shift: weniger Code-Review, mehr Behavior-Verification.
Was du nicht mehr reviewen musst:
- Funktionalität — „Funktioniert der Checkout?" ist eine Frage, die automatische Verification besser beantwortet als ein Mensch, der Code liest. Automatisiere das.
- Styling und Layout — „Sieht die Seite richtig aus?" kann Intent-Verification beantworten. Du musst nicht jede CSS-Änderung reviewen.
- Standard-Patterns — Wenn der Agent ein Formular nach dem gleichen Pattern baut wie die letzten 10 Formulare, musst du das Pattern nicht jedes Mal erneut validieren.
Was du weiterhin reviewen musst:
- Architekturentscheidungen — Sollte das ein eigener Service sein? Ist diese Abstraktion sinnvoll? Baut der Agent technische Schulden auf? Diese Fragen erfordern menschliches Urteil.
- Security — Wird User-Input sanitized? Sind API-Keys exposed? Sind Berechtigungen korrekt? Security-Review bleibt menschlich.
- Datenbank-Migrationen — Schema-Änderungen sind schwer rückgängig zu machen. Hier lohnt sich gründlicher Review.
Die Faustregel: Alles, was durch Beobachtung der laufenden Software geprüft werden kann, automatisieren. Alles, was Urteilsvermögen über Langzeit-Konsequenzen erfordert, manuell reviewen.
Wie verifiziert der Agent seinen eigenen Output?
Über den Self-Verification-Loop: Der Agent baut, verifiziert, fixt und verifiziert erneut — automatisch, ohne dass du eingreifst.
Der Loop:
- Agent bekommt Task: „Add a newsletter signup form to the footer"
- Agent implementiert: erstellt Komponente, bindet sie ein, styled sie
- Agent verifiziert:
aletiq_verify("The footer should contain a newsletter signup form that accepts an email and shows a success message on submit") - Verdict: FAIL — „Form is present but submit button has no click handler. Submitting the form does nothing."
- Agent fixt: fügt den fehlenden onClick-Handler hinzu
- Agent verifiziert erneut: PASS
- Agent meldet: „Done. Newsletter form added and verified."
Du siehst am Ende: fertiges Feature + PASS-Verdict. Statt 60 Minuten Review investierst du 2 Minuten, um das Verdict zu lesen und die Architektur kurz zu prüfen.
Die technischen Details zur MCP-Integration — Setup für Claude Code, Cursor und Copilot — findest du im Artikel MCP-Server für Testing.
Was muss ich noch reviewen und was nicht?
Eine klare Review-Matrix, die dir bei jedem Agent-Output die Entscheidung abnimmt:
| Kategorie | Review-Methode | Aufwand |
|---|---|---|
| Funktioniert das Feature? | Automatisch (Aletiq Verification) | 4,5 Sekunden |
| Navigation und Links korrekt? | Automatisch (Aletiq Verification) | 4,5 Sekunden |
| Formulare funktionieren? | Automatisch (Aletiq Verification) | 4,5 Sekunden |
| Architektur sinnvoll? | Manuell (Code-Review) | 5-15 Minuten |
| Security-Implikationen? | Manuell (Code-Review) | 5-10 Minuten |
| Datenbank-Änderungen? | Manuell (Code-Review) | 10-20 Minuten |
| Styling und Layout? | Optional (Aletiq oder kurzer Blick) | 0-5 Minuten |
| Standard-Patterns? | Überspringen | 0 Minuten |
Vorher: 60-90 Minuten pro Feature (alles manuell reviewen)
Nachher: 10-20 Minuten pro Feature (Verdicts lesen + Architektur/Security prüfen)
Das ist eine Reduktion von 70 bis 80 Prozent des Review-Aufwands — bei gleichbleibender oder besserer Qualität, weil automatische Verification Dinge findet, die beim Code-Lesen durchrutschen (toter Link, fehlender Handler, falscher Redirect).
Wie sieht ein zeiteffizienter Review-Workflow aus?
Der optimierte Tagesablauf mit AI-Agent und automatischer Verification:
Morgens: Tasks definieren
Du definierst 3 bis 5 Tasks für den Agent. Jeder Task enthält den Intent, der verifiziert werden soll:
"Add newsletter signup to footer. Verify: form accepts email and shows success on submit."
"Refactor pricing page with new design tokens. Verify: all three plans visible with working CTAs."
"Fix mobile nav menu. Verify: hamburger menu opens and all links work on mobile viewport."Tagsüber: Agent arbeitet, du arbeitest an anderem
Der Agent implementiert die Tasks autonom, verifiziert seinen Output über den Self-Verification-Loop und meldet Ergebnisse. Du arbeitest parallel an Architekturplanung, Produktstrategie oder eigenen Tasks.
Review-Session: 30 Minuten statt 5 Stunden
- Verdicts lesen (5 Minuten) — Alle PASS? Gut. FAIL oder UNCLEAR? Agent nochmal draufschauen lassen oder manuell prüfen.
- Architektur-Scan (15 Minuten) — Kurzer Blick auf die Diffs: Neue Dateien sinnvoll benannt? Keine unnötigen Abhängigkeiten? Kein offensichtliches Anti-Pattern?
- Security-Check (10 Minuten) — Nur bei relevanten Changes: API-Keys, Auth-Logik, User-Input-Handling.
Ergebnis: 5 Features reviewed in 30 Minuten statt 5 Stunden. Der Agent hat die Funktionalität bereits verifiziert — du prüfst nur noch die Dinge, die menschliches Urteil erfordern.
Wie verhindere ich, dass sich technische Schulden aufbauen?
Berechtigte Sorge: Wenn du weniger Code-Review machst, könnten sich Architekturprobleme einschleichen. Die Lösung: periodische Architektur-Reviews statt per-Commit-Review.
Daily: Automated Verification
Jeder Commit wird automatisch verifiziert. Funktionale Regressionen werden sofort gefangen. Das ist dein Sicherheitsnetz für Tag-zu-Tag-Qualität.
Weekly: Architektur-Review (30-60 Minuten)
Einmal pro Woche schaust du dir die Gesamtarchitektur an: Welche neuen Dateien wurden erstellt? Gibt es duplizierte Logik? Wächst die Komplexität unkontrolliert? Das ist effektiver als bei jedem Commit über Architektur nachzudenken — weil du das große Bild siehst statt einzelne Diffs.
Monthly: Refactoring-Sprint
Ein halber Tag pro Monat für gezieltes Aufräumen: Agent-generierte Patterns konsolidieren, unnötige Abstraktionen entfernen, Naming-Konventionen vereinheitlichen. Auch hier kann der Agent die Arbeit machen — du gibst die Richtung vor.
Dieser Rhythmus — daily automated, weekly architecture, monthly cleanup — verhindert Schulden-Akkumulation ohne den Tages-Workflow zu verlangsamen.
Was wenn der Agent einen Fehler macht, den Verification nicht fängt?
Das passiert — kein Verification-System hat 100 Prozent Detection Rate. Aber es gibt Strategien, um das Risiko zu minimieren.
1. Verification Levels erhöhen
Aletiq bietet sechs Verification Levels (L0 bis L5). Standardmäßig prüft es Existenz, Sichtbarkeit, Content und Verhalten (L0-L3). Für kritische Flows aktiviere zusätzlich:
- L4 (Aesthetic) — Prüft Design-Qualität, fängt Layout-Brüche
- L5 (Journey) — Cross-Page-Kohärenz, prüft ob mehrseitige Flows zusammenpassen
2. Profile verbessern
Je mehr Kontext dein Profile enthält, desto intelligenter urteilt die Judge-Jury. Wenn Fehler durchrutschen, füge die entsprechende Regel zum Profile hinzu: „The pricing page must always show exactly three plans" oder „All external links must open in a new tab."
3. UNCLEAR ernst nehmen
UNCLEAR ist kein „wahrscheinlich okay" — es ist „nicht sicher genug für ein automatisches Urteil". Behandle UNCLEAR wie FAIL: manuell prüfen oder Intent präzisieren. Details dazu im praktischen Guide zur AI-Code-Verification.
4. Production Monitoring als letzte Schicht
Kein Testing-System ersetzt Production-Monitoring. Error-Tracking (Sentry), Uptime-Monitoring und User-Feedback bleiben die letzte Verteidigungslinie — unabhängig davon, wie du verifizierst.
Die Benchmark-Daten zeigen: 91,7 Prozent Overall Accuracy, 97,2 Prozent True Positive Rate. Das bedeutet: Von 100 funktionierenden Features erkennt Aletiq 97 als korrekt. Von 100 kaputten Features erkennt es 79 als kaputt. Die Lücke wird durch Profile-Verbesserung, höhere Verification Levels und Production Monitoring geschlossen.
Skaliert dieser Workflow auch im Team?
Ja — und er wird im Team sogar wertvoller, weil die Review-Asymmetrie mit der Teamgröße wächst.
Bei 5 Entwicklern, jeder mit AI-Agent:
- 5 Agents × 3 bis 5 Features/Tag = 15 bis 25 Features die reviewed werden müssen
- Ohne Automation: 15 bis 25 Stunden Review pro Tag. Unrealistisch.
- Mit Aletiq: Automatische Verification für Funktionalität, menschlicher Review nur für Architektur und Security. Realistisch.
Was im Team zusätzlich hilft:
- Shared Intents — Das Team definiert gemeinsam die kritischen Intents. Jeder Agent verifiziert gegen dieselben Standards.
- CI-Gate als Qualitätstor — Kein Merge ohne PASS auf allen kritischen Intents. Das gilt für alle Entwickler und alle Agents gleichermaßen.
- Team-Dashboard — Zentrale Übersicht: Welche Intents sind PASS, welche FAIL, welche UNCLEAR? Wer hat was geändert? Ab dem Team-Plan (299 Dollar/Monat) verfügbar.
Der Vergleich, wie Claude Code, Cursor und Copilot im Team-Setting funktionieren: Claude Code vs. Cursor vs. Copilot.
Wie starte ich den Shift von Review zu Verification?
Morgen. Nicht nächste Woche, nicht nach dem nächsten Release. Die Setup-Zeit ist minimal, der ROI sofort spürbar.
Tag 1: Intents definieren (15 Minuten)
Identifiziere die 5 Flows, deren Ausfall am teuersten wäre. Formuliere sie als Intents:
aletiq verify "Users can sign up and reach the dashboard" --url https://myapp.com/signup
aletiq verify "The checkout flow is completable" --url https://myapp.com/checkout
aletiq verify "The main navigation leads to all sections" --url https://myapp.com
aletiq verify "The settings page allows profile updates" --url https://myapp.com/settings
aletiq verify "The search returns relevant results" --url https://myapp.com/search?q=testTag 1: MCP einrichten (5 Minuten)
Eine Zeile Config für deinen Agent. Ab sofort verifiziert der Agent seinen eigenen Output.
Tag 2-5: Neuen Workflow testen
Lass den Agent mit Self-Verification arbeiten. Reviewe nur Verdicts + Architektur. Miss die Zeitersparnis. Typisches Ergebnis: 70 bis 80 Prozent weniger Review-Zeit bei gleichbleibender Qualität.
Woche 2: Intents erweitern
Füge Intents für alle kritischen Flows hinzu. Richte ein CI-Gate ein. Der Workflow ist jetzt dein neuer Standard.
Wie Intent-Based Testing funktioniert und wie du gute Intents formulierst: Intent-Based Testing erklärt. Wie Screenshot-Diffing sich davon unterscheidet: Screenshot-Diffing vs. Intent-Based Verification.
Free Tier: 50 Verifications pro Monat. Genug um den Workflow zu testen und den ROI zu sehen.
Hör auf, Bottleneck zu sein. Lass den Agent verifizieren, was er baut — du steuerst die Richtung.