Why AI Agent Testing Is Different From Traditional Testing
AI agents break code at the seams between components and flows. Why traditional tests miss it and what behavioral verification actually means.
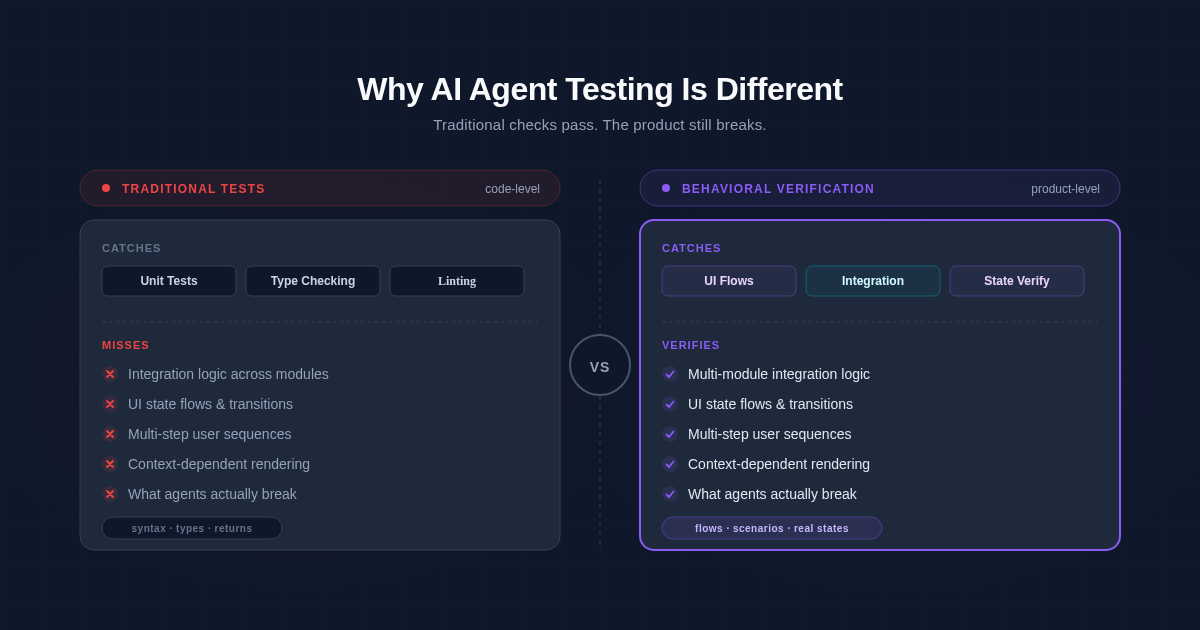
AI agents break code at the seams — between components, across multi-step flows, in the gap between "this compiles" and "this does the right thing." Traditional tests verify that functions return the expected values in isolation. AI-generated bugs live at integration boundaries, where your test suite has no eyes.
This is why developers using Claude Code, Cursor, Copilot, and Windsurf keep finding bugs in production even when their CI pipeline is green. The problem is not that AI-generated code is poorly written. The problem is that the tests were written with the same assumptions the AI used to write the code.
Why does AI-generated code pass tests but fail in production?
AI-generated code passes tests because it is usually syntactically correct, type-safe, and follows the patterns of the surrounding codebase. The failure mode is semantic: the code does a thing that looks right but is not actually what the system requires in context. According to the 2025 GitHub Developer Survey, 73% of developers using AI coding assistants report spending more time reviewing code than writing it — and review fatigue is where semantic bugs slip through.
Consider a real pattern we see daily at Aletiq. An agent writes a feature that calls POST /api/users with a name field. The TypeScript compiles because the types are not shared with the backend. The unit test mocks the fetch call and asserts the mock was called. The integration test hits a mock server with the same shape. Everything is green. In production, the real endpoint expects user_name in snake_case and returns a 400. The test did not fail because it was shaped by the same wrong assumption as the code.
What bugs do AI coding agents actually produce?
AI agents generate a recognizable class of defects that handwritten code rarely produces in the same density. After reviewing thousands of agent-generated diffs, five categories dominate:
- Wrong component variant. The agent picks
<Button variant="primary">when the design system expects<Button variant="cta">for a checkout context. Unit tests for the Button component pass. No visual regression catches it. The page ships with the wrong affordance. - API called with wrong parameters. The agent invents a plausible parameter name or confuses camelCase with snake_case. Without end-to-end type sharing between client and server, TypeScript is silent. The mocked test passes. The real endpoint returns 400.
- State desync in multi-step flows. Step 2 of a form reads from a context that step 1 never updated, because the agent generated both steps independently and forgot the setter. The happy-path E2E test covers steps in order and passes. Back-navigation, tab-switching, and refresh all break silently.
- Stale closures in hooks. The agent writes a
useEffectthat captures a stale state reference. The ESLint rule warns. The agent adds aneslint-disablecomment because that looks like what previous fixes did. The bug is timing-dependent and never reproduces in the test environment. - Wrong event handler wired. The agent puts
onClick={handleSubmit}on a form's submit button instead ofonSubmiton the form. Cypress clicks the button and the test passes. Users who press Enter in a text field never trigger submission.
These are not random mistakes. They cluster at the boundary where local correctness meets global context — exactly the boundary that unit tests cannot see and integration tests rarely probe.
Learn more in our post Claude Code vs. Cursor vs. Copilot: Wie verifizierst du, was sie bauen?.
Are traditional unit tests enough for AI-generated code?
Traditional unit tests verify the wrong layer. A unit test confirms that calculateDiscount(100, 0.1) returns 90. That is useful. It does not tell you whether calculateDiscount should have been called at all, with those inputs, at that point in the flow, on that code path, for that user. The AI agent's most common failures are about whether and when, not how.
A senior developer with 90% test coverage and strict TypeScript will catch many of these bugs eventually — usually in review, sometimes in staging, occasionally in production. The question is not whether traditional tests can catch them. It is whether they catch them efficiently enough when you are reviewing hundreds of AI-generated lines per day. Review fatigue is real. Pattern recognition degrades. Green checks become trust signals even when they verify nothing meaningful.
What is behavioral verification and how is it different?
Behavioral verification checks what the system actually does from the outside, without sharing assumptions with the code that produced it. The key word is independent. A unit test written alongside a feature inherits the author's mental model. If that author is an AI agent that hallucinated the endpoint shape, the test will confirm the hallucination. A behavioral check that drives the real UI, hits the real API, and observes the real state has no such shared blind spot.
It is worth being honest: behavioral verification is not a magical new test category. It is a principled version of what "good E2E testing" has always aspired to be. The difference in an AI-agent workflow is that the verification layer must be generated or reviewed by a different source of truth than the code under test. When a human writes code and a human writes tests, some independence is assumed. When an agent writes both, that assumption collapses — unless the verification explicitly comes from the product intent, not the implementation.
Learn more in our post Intent-Based Testing erklärt: Warum du Tests in Plain English schreiben solltest.
When do Playwright and Cypress tests catch AI bugs — and when do they miss them?
Playwright and Cypress catch a subset of AI failures and miss the rest. They catch happy-path regressions reliably. They miss the failure modes that depend on state history, concurrency, back-navigation, keyboard interaction, or subtle visual correctness. More importantly, they miss anything the test author did not think to cover — and when the test author is the same agent that wrote the feature, the blind spots in the code and the test overlap perfectly.
A concrete pattern: an agent generates a new checkout step and a matching Playwright test. The test fills the form, clicks Submit, asserts the URL changes. The real bug is that the form submits to the wrong endpoint, and the agent's backend mock happens to accept any request. The URL changes. The test is green. The order never reaches the warehouse.
Learn more in our post Playwright vs. Aletiq: Warum klassische E2E-Tests bei AI-generiertem Code versagen.
Why is review fatigue making the problem worse?
Code review has always been the last line of defense against semantic bugs. It is breaking down under AI velocity. When a developer writes 200 lines of code a day, they can hold the intent in their head and review it carefully. When an AI agent produces 2,000 lines in the same day, reviewers start skimming. They look at the diff shape, confirm the tests are green, check for obvious smells, and approve. The 73% figure from the 2025 GitHub Developer Survey — more time reviewing than writing — is not a sign that review is working. It is a sign that review is becoming the bottleneck, and bottlenecks get cut.
The uncomfortable truth is that review and test-writing were a single implicit contract: the reviewer understood what the code should do and verified that the tests enforced it. AI agents break both halves of the contract at once. They generate the code and the tests, both plausible, both shaped by the same prior. The reviewer inherits a choice between careful manual verification (slow) and trusting the green checks (wrong).
Learn more in our post Mein AI-Agent baut schneller als ich reviewen kann. Was jetzt?.
Can you just write more E2E tests to close the gap?
This is the honest counterargument and it deserves an honest answer. Yes, in principle, a sufficiently thorough Playwright or Cypress suite can catch most AI-generated bugs. In practice, three things break down.
First, E2E tests are expensive to write and maintain. Doubling the suite to cover AI failure modes doubles the flakiness, the runtime, and the maintenance cost. Second, E2E tests written by the same agent that wrote the feature inherit the same blind spots — the test and the bug are correlated. Third, the coverage problem is not "more tests of the same kind." The gap is in the categories of assertion, not the count. You need checks that observe state transitions, not just final states. You need checks that verify network calls match a real contract, not a mocked one. You need checks that verify UI semantics, not just UI presence.
More Playwright tests close part of the gap. They do not close the part where the test author and the code author are the same agent with the same wrong assumptions. That part requires the verification to come from a different source — a human product spec, a real API contract, or a verification pass that was not trained on the same diff.
What should developers actually change in their testing workflow?
Three changes matter more than any specific tool choice.
- Decouple verification from implementation. If an AI agent writes the feature, a human or a separate verification pass should define what "correct" means. Not the tests — the intent. Tests should be derived from that intent independently.
- Check real contracts, not mocks. Shared types across client and server, contract tests that run against the real API, and schema validation at every boundary. Mocks are where AI hallucinations hide.
- Assert state transitions, not just final states. Multi-step flows break because of what happens between steps, not because of where they end up. Your test should observe the context at every step, not just the URL at the last one.
None of this requires throwing out your existing suite. It requires adding a verification layer whose job is to challenge the AI's assumptions rather than confirm them.
How does behavioral verification fit into existing CI pipelines?
Behavioral verification runs after your existing tests, not instead of them. Unit tests stay where they are — they are still the fastest signal for logic errors. Integration tests keep their role. The new layer sits at the point where a PR would otherwise be approved: it drives the real application against the product intent and reports on what the application actually does, independently of what the tests say it does.
The practical requirement is that this layer runs on ephemeral environments or preview deployments, because it needs to observe real behavior. Most teams already have preview deploys for frontend PRs. Adding a verification pass on top of those is a smaller lift than rewriting the test pyramid.
Learn more in our post CI/CD für AI-generierte Features: Verification als Pipeline-Step.
What is the realistic path forward for testing AI-generated code?
The realistic path is to stop pretending that the existing test pyramid is enough and start treating AI-generated code as a different trust category. Not untrustworthy — just differently trustworthy. The code is fast, syntactically clean, and mostly right. The failure distribution is different: fewer typos, more semantic drift. The verification layer needs to match that distribution.
At Aletiq we build verification tooling for exactly this gap. We see the same five failure categories — wrong component, wrong parameters, state desync, stale closures, wrong handler — across Claude Code, Cursor, Copilot, and Windsurf workflows. The agent tool does not matter much. The failure shape is consistent because the underlying mechanism is consistent: fast generation of locally correct code with global context gaps.
If you are shipping AI-generated code and trusting your Playwright suite to catch everything, try a behavioral verification pass on your next feature. Run it on a preview deploy, feed it the product intent separately from the implementation, and see what it finds. If the answer is "nothing," your suite is better than most. If the answer is "three things we would have shipped," you have found the gap this post is about.