Wie teste ich Code, den mein AI-Agent geschrieben hat? Ein praktischer Guide
AI-generierter Code braucht Verification, nicht nur Code-Review. Praktischer Guide: Intent-Based Verification, CI/CD-Integration und Self-Healing-Loop mit AI-Agents.
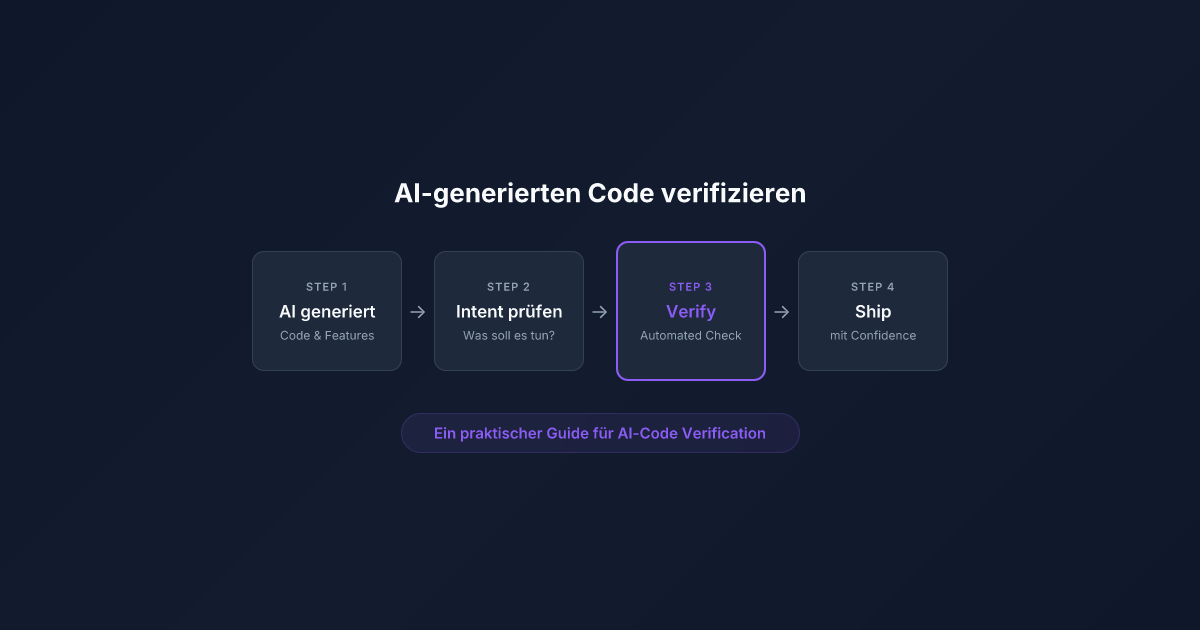
AI-generierter Code braucht Verification, nicht nur Code-Review. Klassische Tests brechen bei jedem Rewrite, manuelles Durchklicken skaliert nicht. Der praktische Ansatz: Intent-Based Verification, die prüft ob die Software ihren Zweck erfüllt — unabhängig davon, wie der Code aussieht. Dieser Guide zeigt den kompletten Workflow: vom ersten Intent bis zur CI/CD-Integration.
Keine Theorie, keine Architektur-Diskussion — sondern konkrete Schritte, die du heute noch umsetzen kannst.
Warum ist AI-generierter Code schwerer zu testen als manuell geschriebener?
Weil die Grundannahmen klassischen Testens nicht mehr gelten, sobald ein AI-Agent den Code schreibt.
Drei fundamentale Unterschiede:
- Höhere Änderungsrate — Ein Entwickler schreibt und refactored eine Komponente über Tage oder Wochen. Ein AI-Agent kann dieselbe Komponente in 5 Minuten komplett neu schreiben. Bei Dutzenden AI-generierten Changes pro Tag veralten Tests schneller als du sie aktualisieren kannst.
- Weniger Verständnis für Interna — Wenn du Code selbst schreibst, verstehst du jede Zeile. Bei AI-generiertem Code überfliegst du das Ergebnis, checkst ob es „ungefähr richtig" aussieht und machst weiter. Subtile Fehler — ein vergessener Click-Handler, ein falscher API-Endpunkt, eine fehlende Null-Check — fallen beim Überfliegen nicht auf.
- Code sieht korrekt aus, verhält sich aber falsch — AI-Agents produzieren syntaktisch korrekten, gut formatierten Code, der alle Linting-Rules besteht. Aber „kompiliert" heißt nicht „funktioniert". Ein Button ohne onClick-Handler rendert perfekt, tut aber nichts. Eine API-Route mit falschem Endpunkt gibt keine Compile-Fehler, liefert aber keine Daten.
Das Kernproblem: Die Verifikations-Methoden, die bei menschlicher Entwicklung funktionieren (Code-Review, Unit-Tests, manuelle QA), skalieren nicht mit der Geschwindigkeit, mit der AI-Agents Code produzieren.
Reicht ein Code-Review bei AI-generiertem Code?
Für Architekturentscheidungen und Security: ja. Für funktionale Korrektheit: nein.
Warum Code-Review allein nicht ausreicht:
- AI produziert überzeugend aussehenden Code — Claude, GPT und Copilot generieren Code, der professionell formatiert ist, sinnvolle Variablennamen verwendet und logisch aufgebaut wirkt. Genau das macht es schwerer, Fehler zu erkennen — dein Gehirn interpretiert „sieht professionell aus" als „ist wahrscheinlich korrekt".
- Review-Fatigue bei hohem Volumen — Wenn dein AI-Agent 20 bis 30 Changes pro Tag produziert, sinkt die Review-Qualität zwangsläufig. Studien zeigen, dass die Defect-Detection-Rate nach 60 bis 90 Minuten Code-Review drastisch abfällt. Bei AI-Geschwindigkeit erreichst du diese Grenze schnell.
- Review prüft Code, nicht Verhalten — Du liest die Diff und fragst: „Sieht das richtig aus?" Aber die eigentliche Frage ist: „Tut die App noch das, was sie soll?" Diese Frage beantwortet kein Code-Review — nur ein Verhaltenstest.
Code-Review bleibt sinnvoll für: Architekturentscheidungen (sollte das ein eigener Service sein?), Security (wird User-Input sanitized?), und Konventionen (passt das zum bestehenden Code-Stil). Aber für die Frage „funktioniert der Checkout noch?" brauchst du Verification, nicht Review.
Warum brechen klassische Tests bei AI-generierten Änderungen?
Weil klassische E2E-Tests an Implementierungsdetails gekoppelt sind — CSS-Selektoren, DOM-Struktur, exakte Texte. Und genau diese Details ändert ein AI-Agent bei jedem Refactoring.
Ein Beispiel:
// Dein Playwright-Test
await page.locator('[data-testid="submit-btn"]').click();
await expect(page.locator('.success-message')).toBeVisible();Der AI-Agent refactored die Komponente und benennt data-testid="submit-btn" in data-testid="form-submit" um. Oder ersetzt die CSS-Klasse .success-message durch eine Tailwind-Klasse. Oder extrahiert die Komponente in eine eigene Datei und ändert die DOM-Hierarchie.
In jedem dieser Fälle: Das Formular funktioniert weiterhin korrekt. Aber der Test schlägt fehl. Du musst den Test anpassen, obwohl kein Bug existiert.
Multipliziere das mit 50 Tests und 20 AI-generierten Changes pro Tag — und du verbringst mehr Zeit mit Test-Maintenance als mit Feature-Entwicklung.
Die technische Erklärung und den direkten Vergleich zwischen Playwright und Intent-Based Verification findest du im Artikel Playwright vs. Aletiq.
Was sollte ich nach jedem AI-generierten Change verifizieren?
Nicht alles — sondern die Dinge, deren Ausfall echten Schaden verursacht. Hier eine praktische Checkliste:
Kritisch (nach jedem Change verifizieren):
- Navigation funktioniert — alle Hauptlinks führen zu den richtigen Seiten
- CTAs verlinken korrekt — der wichtigste Conversion-Pfad ist intakt
- Formulare submitten — Kontakt, Signup, Checkout senden Daten ab
- Daten laden — Dashboard, Produktlisten, Suchergebnisse zeigen echte Inhalte
- Kritische Flows sind komplett — Signup → Onboarding → erste Aktion, oder Produkt → Warenkorb → Checkout
Wichtig (bei größeren Changes verifizieren):
- Responsive Layout — Seite ist auf Mobile und Desktop nutzbar
- Error States — was passiert bei ungültiger Eingabe?
- Auth-Flows — Login, Logout, Password-Reset funktionieren
Als Aletiq-Intents formuliert:
# Kritische Intents (nach jedem Change)
aletiq verify "All main navigation links should lead to their respective pages" --url https://myapp.com
aletiq verify "The primary CTA should navigate to signup" --url https://myapp.com
aletiq verify "The contact form should be submittable" --url https://myapp.com/contact
aletiq verify "The dashboard should display user data after login" --url https://myapp.com/dashboard
aletiq verify "The checkout flow should be completable from the product page" --url https://myapp.com/products/15 Intents, 5 × 4,5 Sekunden = unter 25 Sekunden für einen kompletten Verification-Durchlauf deiner kritischen Flows.
Wie sieht ein praktischer Verification-Workflow aus?
Der tägliche Workflow mit AI-Agent + Aletiq in vier Schritten:
Schritt 1: Feature bauen lassen
# In Claude Code, Cursor oder einem anderen AI-Agent
"Refactor the pricing page to use the new design system components"Der AI-Agent schreibt den Code, refactored die Komponenten, aktualisiert die Imports.
Schritt 2: Verifizieren
aletiq verify "The pricing page should display all three plans with correct CTAs" --url http://localhost:3000/pricing
aletiq verify "Each plan CTA should navigate to the checkout with the correct plan preselected" --url http://localhost:3000/pricing4,5 Sekunden pro Intent. Du bekommst ein klares Verdict: PASS, UNCLEAR oder FAIL.
Schritt 3: Bei FAIL korrigieren lassen
# Zurück zum AI-Agent
"The pricing CTA for the Pro plan navigates to /checkout but doesn't preselect the Pro plan. Fix the URL parameter."Der Agent fixt den Bug. Du verifizierst erneut. PASS.
Schritt 4: Committen
Code ist verifiziert, Intents sind grün, Commit geht raus. Kein manuelles Durchklicken, keine Test-Maintenance, kein „hoffentlich funktioniert das noch".
Dieser Loop — bauen → verifizieren → fixen → committen — dauert Minuten statt Stunden. Und er skaliert mit jeder Anzahl von AI-generierten Changes.
Kann mein AI-Agent die Verification selbst auslösen?
Ja — und das ist der eigentliche Game-Changer. Aletiq ist MCP-nativ (Model Context Protocol) und funktioniert mit allen gängigen AI-Coding-Tools.
Unterstützte AI-Agents: Claude Code, Cursor, Codex, Gemini, GitHub Copilot, Windsurf, Aider, Continue, Cline und Devin.
Der Self-Verification-Loop:
- Du gibst dem Agent einen Task: „Refactor the hero section"
- Der Agent schreibt den Code
- Der Agent ruft
aletiq verify "The hero CTA should navigate to signup" --url http://localhost:3000auf - Bei PASS: Agent meldet „Done, verified"
- Bei FAIL: Agent liest das Verdict, identifiziert das Problem und fixt es selbst
- Zurück zu Schritt 3, bis PASS
Der Agent baut, verifiziert und fixt in einer Schleife — ohne dass du eingreifen musst. Du bekommst am Ende fertigen, verifizierten Code.
Das funktioniert, weil Aletiq-Verdicts maschinenlesbar sind: Klares PASS/FAIL, strukturierte Begründung, Evidenz in Form von Screenshots. Der AI-Agent kann das Verdict parsen und darauf reagieren.
Wie integriere ich Verification in meine CI/CD-Pipeline?
Als Gate in GitHub Actions oder GitLab CI — PRs werden nur gemergt, wenn alle Intents PASS sind.
Beispiel: GitHub Actions
name: Verify
on: [pull_request]
jobs:
verify:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Start app
run: npm start &
- name: Wait for app
run: npx wait-on http://localhost:3000
- name: Verify critical intents
run: |
aletiq verify "Navigation links lead to correct pages" --url http://localhost:3000
aletiq verify "Signup flow is completable" --url http://localhost:3000/signup
aletiq verify "Pricing page shows all plans" --url http://localhost:3000/pricingJeder FAIL blockiert den Merge. Kein AI-generierter Change geht in Production, ohne dass die kritischen Flows verifiziert sind.
Vorteile gegenüber Playwright in CI:
- Keine Test-Dateien, die gewartet werden müssen
- Keine Selector-Updates bei UI-Refactoring
- Keine Flaky Tests durch Timing-Probleme
- Intent-Definitionen sind stabil über Monate und Jahre
Was mache ich bei einem UNCLEAR-Verdict?
UNCLEAR bedeutet: Die Multi-Model-Jury konnte sich nicht einstimmig auf PASS oder FAIL einigen. Das passiert in drei typischen Situationen:
1. Intent ist zu vage
# Zu vage
aletiq verify "The page should work" --url https://myapp.com
# Besser
aletiq verify "The page should load within 5 seconds and display the hero section with a visible CTA" --url https://myapp.comLösung: Intent präzisieren. Je spezifischer der Intent, desto eindeutiger das Verdict.
2. UI ist ambivalent
Der CTA existiert, aber ist teilweise von einem Cookie-Banner verdeckt. Technisch sichtbar, praktisch schwer klickbar. Die Jury ist sich nicht einig, ob das PASS oder FAIL ist.
Lösung: Profile ergänzen. Definiere im Project Profile, dass CTAs vollständig sichtbar und klickbar sein müssen, ohne andere Elemente zu verschieben.
3. Edge Case im Verhalten
Der Signup-Flow funktioniert, aber nach dem Submit erscheint eine Erfolgsmeldung erst nach 8 Sekunden. Funktioniert es? Ja. Ist das akzeptabel? Darüber sind die Models uneins.
Lösung: In diesen Fällen ist manuelles Prüfen sinnvoll. UNCLEAR ist kein Fehler des Systems — es ist eine ehrliche Aussage: „Das erfordert menschliches Urteil." Besser als ein falsches PASS oder ein falsches FAIL.
UNCLEAR-Rate im Benchmark liegt unter 5 Prozent. Bei präzise formulierten Intents und einem gepflegten Profile sinkt sie weiter.
Wie viele Intents brauche ich für mein Projekt?
Weniger als du denkst. Qualität schlägt Quantität — 10 gute Intents fangen mehr echte Bugs als 100 vage.
Faustregeln nach Projektgröße:
| Projekttyp | Intents | Fokus |
|---|---|---|
| Landing Page / MVP | 5-10 | Navigation, CTAs, Kernbotschaft sichtbar |
| SaaS-App (Early Stage) | 15-25 | Signup, Login, Kernfeature, Billing |
| Production App | 30-50 | Alle kritischen Flows + Edge Cases |
| E-Commerce | 20-40 | Produktsuche, Warenkorb, Checkout, Account |
Wie du die richtigen Intents findest:
- Frage dich: „Wenn das kaputt geht, verliere ich Kunden oder Geld?" — Alles mit Ja wird ein Intent.
- Formuliere aus Nutzersicht: „Der User sollte..." statt „Der Button sollte..."
- Starte mit den offensichtlichen 5 und erweitere, wenn du FAIL-Verdicts für Dinge bekommst, die du nicht abgedeckt hast.
Mit dem Free Tier (50 Verifications/Monat) kannst du 10 Intents 5-mal im Monat verifizieren — genug für wöchentliche Releases einer Früh-Phase-App.
Wie starte ich heute noch mit AI-Code-Verification?
In 5 Minuten, ohne Signup, ohne Konfiguration:
Schritt 1: Ersten Intent formulieren
Denke an die eine Sache in deiner App, die auf keinen Fall kaputt gehen darf. Das ist dein erster Intent.
Schritt 2: Verifizieren
aletiq verify "Users should be able to complete the signup flow" --url https://myapp.com/signup4,5 Sekunden. PASS, UNCLEAR oder FAIL — mit Begründung und Screenshots.
Schritt 3: In den Workflow einbauen
Rufe aletiq verify nach jedem AI-generierten Change auf. Oder integriere es als MCP-Tool, damit dein AI-Agent es selbst aufruft. Oder füge es als CI-Gate hinzu.
Schritt 4: Intents erweitern
Fünf Intents heute, zehn nächste Woche, zwanzig nächsten Monat. Dein Verification-Netz wächst mit deinem Projekt — ohne Maintenance-Schulden.
Mehr zum technischen Hintergrund: Wie sich Intent-Based Verification von Screenshot-Diffing unterscheidet, beschreiben wir im Vergleich Screenshot-Diffing vs. Intent-Based Verification.
Probiere Aletiq jetzt aus: aletiq verify auf deinem Projekt — in 5 Sekunden weißt du, ob dein AI-generierter Code tut, was er soll.