Playwright vs. Aletiq: Warum klassische E2E-Tests bei AI-generiertem Code versagen
Playwright-Tests brechen bei AI-generiertem Code. Aletiq verifiziert Intent statt Selektoren — keine Test-Maintenance, keine brittle Selectors. Benchmark: 91.7% Accuracy.
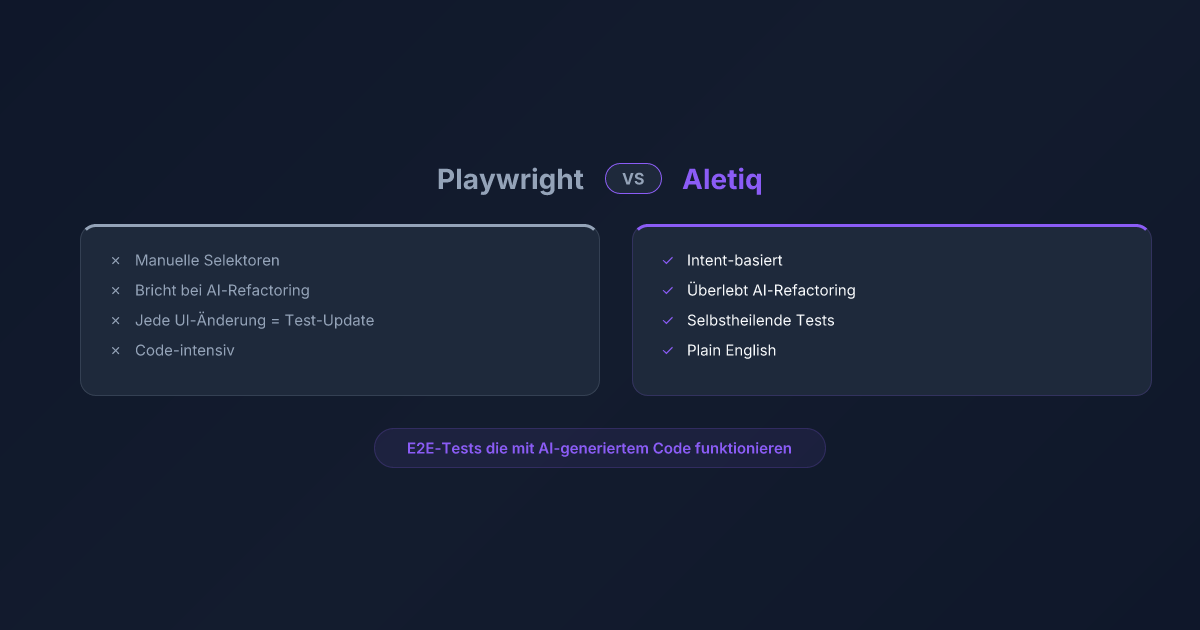
Klassische Playwright-Tests brechen, sobald ein AI-Agent die UI umschreibt — neue Selektoren, geänderte Struktur, umbenannte Klassen. Aletiq löst das Problem, indem es nicht Code testet, sondern Intent verifiziert: „Funktioniert der CTA noch?" statt expect(locator('.btn-primary')).toBeVisible(). Das Ergebnis: keine Test-Maintenance, keine falschen Grüne, keine brittle Selectors.
Dieser Artikel zeigt, warum klassische E2E-Tests in Codebases mit AI-generierten Änderungen systematisch versagen, wie Intent-Verification funktioniert — und wann Playwright trotzdem die bessere Wahl ist.
Warum brechen Playwright-Tests bei AI-generiertem Code?
Weil Playwright-Tests an Implementierungsdetails gekoppelt sind — und AI-Agents diese Details bei jedem Durchlauf anders schreiben.
Ein typischer Playwright-Test sieht so aus:
await page.locator('.hero-section .cta-button').click();
await expect(page).toHaveURL('/pricing');Dieser Test funktioniert, solange die CSS-Klasse .hero-section existiert, das CTA-Element die Klasse .cta-button hat und die URL exakt /pricing lautet. Ändert ein AI-Agent auch nur eines dieser Details — und das passiert bei jedem größeren Refactoring — schlägt der Test fehl, obwohl die Funktionalität identisch ist.
Drei Gründe, warum AI-generierter Code Playwright-Tests systematisch bricht:
- Selektoren veralten sofort — Claude Code, Cursor oder Copilot benennen CSS-Klassen um, refactoren Komponentenstrukturen oder ersetzen
div-Hierarchien durch semantische HTML-Elemente. Jede dieser Änderungen invalidiert bestehende Selektoren. - Struktur ändert sich bei gleichem Verhalten — Ein AI-Agent extrahiert eine Inline-Komponente in eine eigene Datei, verschiebt einen Button in einen neuen Wrapper oder ersetzt eine Custom-Lösung durch eine Library-Komponente. Das Verhalten bleibt gleich, aber der DOM-Baum sieht komplett anders aus.
- Tests prüfen das Falsche — Playwright-Tests prüfen, ob ein spezifisches Element existiert und einen bestimmten Zustand hat. Sie prüfen nicht, ob die Software ihren Zweck erfüllt. Ein Test kann grün sein, obwohl der User den CTA nicht findet, weil er hinter einem Cookie-Banner versteckt ist.
Das Kernproblem: Playwright-Tests sind code-gekoppelt. In einer Welt, in der AI den Code ständig umschreibt, ist Code-Kopplung ein Wartungs-Albtraum.
Was ist der Unterschied zwischen Code-Testing und Intent-Verification?
Code-Testing prüft Implementierungsdetails. Intent-Verification prüft, ob die Software ihren Zweck erfüllt. Der Unterschied ist fundamental.
Code-Testing (Playwright):
// Prüft: Hat das Element mit data-testid="cta" den Text "Start Free"?
await expect(page.getByTestId('cta')).toHaveText('Start Free');
// Prüft: Navigiert der Klick zu /pricing?
await page.getByTestId('cta').click();
await expect(page).toHaveURL('/pricing');Dieser Test bricht, wenn das data-testid umbenannt wird, der Button-Text sich ändert oder die URL-Struktur angepasst wird — auch wenn die Funktion weiterhin korrekt ist.
Intent-Verification (Aletiq):
aletiq verify "The main call-to-action should navigate the user to the pricing page" --url https://myapp.comDieser Intent bleibt stabil, egal wie oft der AI-Agent die Implementierung ändert. Ob der Button „Start Free", „Get Started" oder „View Plans" heißt — solange er den User zur Pricing-Seite bringt, ist der Intent erfüllt.
Der entscheidende Unterschied:
| Dimension | Playwright (Code-Testing) | Aletiq (Intent-Verification) |
|---|---|---|
| Prüft | Selektoren, Text, URLs | Verhalten und Zweck |
| Gekoppelt an | Implementierung | Business-Intent |
| Bricht bei UI-Refactoring? | Ja | Nein |
| Bricht bei AI-Rewrite? | Fast immer | Nur wenn Verhalten sich ändert |
| Maintenance | Laufend (Selektoren, Assertions) | Keine (Intents sind stabil) |
| Sprache | JavaScript/TypeScript | Natürliche Sprache |
Intent-Verification fragt: „Macht die Software noch das, was sie soll?" Code-Testing fragt: „Sieht der Code noch so aus, wie ich es erwarte?" In einer AI-generierten Codebase ist nur die erste Frage zuverlässig beantwortbar.
Wie funktioniert Aletiq unter der Haube?
Aletiq trennt Verifikation in drei unabhängige Schritte — inspiriert vom Prinzip der Gewaltenteilung. Kein Schritt kennt die internen Details der anderen.
Schritt 1: Planner (Legislative)
Der Planner empfängt deinen Intent in natürlicher Sprache und übersetzt ihn in einen Ausführungsplan: Welche Seite öffnen, welche Elemente suchen, welche Aktionen durchführen, welche Screenshots machen. Gleichzeitig definiert er die Bewertungskriterien für den Judge — unsichtbar für den Runner.
Schritt 2: Runner (Exekutive)
Der Runner führt den Plan lokal auf deiner Maschine aus. Er navigiert die Seite, macht Screenshots (vorher/nachher), sammelt DOM-Informationen und dokumentiert das Verhalten. Der Runner weiß nicht, wie seine Beobachtungen bewertet werden — er sammelt nur Evidenz.
Schritt 3: Judge (Judikative)
Eine Multi-Model-Jury aus drei unabhängigen LLMs — Claude, Gemini und GPT — bewertet die gesammelten Beobachtungen gegen den ursprünglichen Intent. Alle drei müssen einstimmig urteilen. Das Ergebnis: PASS, UNCLEAR oder FAIL — mit Begründung und Evidenz.
Die Trennung ist bewusst: Der Runner kann nicht „cheaten", weil er die Bewertungskriterien nicht kennt. Der Judge kann keine Evidenz erfinden, weil er nur sieht, was der Runner tatsächlich beobachtet hat. Und der Planner hat keinen Zugang zur Ausführung.
Nutzt Aletiq selbst Playwright?
Ja — der Runner ist auf Playwright aufgebaut. Aletiq ersetzt Playwright nicht als Browser-Automation-Tool, sondern als Testing-Framework.
Der Unterschied liegt nicht in der Browser-Steuerung, sondern in drei Schichten darüber:
- Wer schreibt die Testlogik? — Bei Playwright: du. Bei Aletiq: der Planner (AI), basierend auf deinem Intent.
- Wer wartet die Tests? — Bei Playwright: du, bei jeder UI-Änderung. Bei Aletiq: niemand, weil Intents stabil sind.
- Wer bewertet die Ergebnisse? — Bei Playwright: deine Assertions (
expect(...).toBe(...)). Bei Aletiq: eine Multi-Model-Jury, die Verhalten statt Code bewertet.
Aletiq nutzt Playwright für das, was Playwright gut kann: Browser steuern, Seiten navigieren, Screenshots machen, DOM auslesen. Aber die Intelligenz — was getestet wird, wie es bewertet wird und ob das Ergebnis sinnvoll ist — liegt in den AI-Schichten darüber.
Du kannst dir Aletiq als Playwright vorstellen, bei dem du keine Tests mehr schreibst, sondern nur noch beschreibst, was funktionieren soll.
Wie sieht ein Aletiq-Verify im Vergleich zu einem Playwright-Test aus?
Ein konkretes Beispiel: Überprüfen, ob die Navigation einer Landing Page funktioniert.
Playwright (30+ Zeilen):
import { test, expect } from '@playwright/test';
test('navigation links work correctly', async ({ page }) => {
await page.goto('https://myapp.com');
// Check hero CTA
const ctaButton = page.locator('[data-testid="hero-cta"]');
await expect(ctaButton).toBeVisible();
await expect(ctaButton).toHaveText('Start Free Trial');
await ctaButton.click();
await expect(page).toHaveURL('/pricing');
// Go back and check nav links
await page.goto('https://myapp.com');
const docsLink = page.locator('nav a[href="/docs"]');
await expect(docsLink).toBeVisible();
await docsLink.click();
await expect(page).toHaveURL('/docs');
// Check pricing nav
await page.goto('https://myapp.com');
const pricingLink = page.locator('nav a[href="/pricing"]');
await expect(pricingLink).toBeVisible();
await pricingLink.click();
await expect(page).toHaveURL('/pricing');
});Aletiq (3 Befehle):
aletiq verify "The hero CTA should navigate to the pricing page" --url https://myapp.com
aletiq verify "The docs link in the navigation should lead to documentation" --url https://myapp.com
aletiq verify "The pricing link in the navigation should lead to pricing" --url https://myapp.comDer Playwright-Test bricht, wenn data-testid="hero-cta" umbenannt wird, der CTA-Text sich ändert oder die Navigation-Struktur refactored wird. Die Aletiq-Intents funktionieren, solange die Navigation existiert und korrekt verlinkt — egal wie die Implementierung aussieht.
Und der wichtigste Unterschied: Wenn ein AI-Agent die gesamte Navigation-Komponente neu schreibt, schreiben sich die Aletiq-Intents nicht um. Der Playwright-Test muss komplett überarbeitet werden.
Was kostet Test-Maintenance bei Playwright wirklich?
Mehr als die meisten Teams zugeben wollen. Test-Maintenance ist der versteckte Zeitfresser in jeder E2E-Test-Suite.
Die typischen Maintenance-Aufwände:
- Selector-Pflege — Jedes UI-Refactoring erfordert Selector-Updates in den Tests. Ein größeres Redesign kann Dutzende Tests invalidieren. Bei Teams, die AI-Agents für Feature-Entwicklung nutzen, passiert das bei jedem Sprint.
- Flaky-Test-Debugging — Tests, die mal grün, mal rot sind, ohne dass sich die Software geändert hat. Race Conditions, Timing-Probleme, instabile Selektoren. Flaky Tests sind das häufigste Argument gegen E2E-Tests überhaupt.
- Assertion-Updates — Texte ändern sich, URLs werden umstrukturiert, Default-Werte angepasst. Jede dieser Änderungen erfordert ein Update in den Assertions — oder der Test schlägt fehl, obwohl alles korrekt funktioniert.
- Test-Infrastruktur — Playwright-Tests brauchen Browser-Binaries, CI-Konfiguration, parallele Ausführung, Screenshot-Vergleich. Diese Infrastruktur will gewartet, aktualisiert und skaliert werden.
Erfahrungswerte aus der Praxis zeigen: 30 bis 40 Prozent der gesamten Testing-Zeit eines Teams fließt in Maintenance bestehender Tests — nicht in das Schreiben neuer Tests. In Codebases mit AI-generierten Änderungen steigt dieser Anteil weiter, weil die Änderungsrate höher ist als bei rein menschlicher Entwicklung.
Bei Aletiq fällt dieser Aufwand komplett weg. Intents in natürlicher Sprache veralten nicht, weil sie an Verhalten gekoppelt sind, nicht an Implementierung.
Wie genau ist Intent-Verification?
Aletiq wird gegen einen Benchmark von 265 Test Cases mit Cypress/Playwright Ground Truth gemessen — echte E2E-Tests aus Open-Source-Projekten, die als Wahrheitsgrundlage dienen.
Aktuelle Benchmark-Ergebnisse:
| Metrik | Wert |
|---|---|
| Overall Accuracy | 91,7% |
| True Positive Rate (korrekte PASS) | 97,2% |
| True Negative Rate (korrekte FAIL-Erkennung) | 78,7% |
| Durchschnittliche Latenz | 4,5 Sekunden pro Verification |
Was diese Zahlen bedeuten:
- 97,2% True Positive Rate — Wenn etwas funktioniert, erkennt Aletiq das in 97,2 Prozent der Fälle korrekt. Kaum False Negatives, die funktionierenden Code als fehlerhaft melden.
- 78,7% True Negative Rate — Wenn etwas kaputt ist, erkennt Aletiq das in 78,7 Prozent der Fälle. Das Ziel für Launch liegt bei 99,9 Prozent — subtile Fehler wie minimale Farbabweichungen oder Reorder-Bugs sind aktuell die größte Herausforderung.
- 4,5 Sekunden Latenz — Schnell genug für den Dev-Loop. Du bekommst Feedback in der Zeit, die du für einen Schluck Kaffee brauchst.
Der Benchmark umfasst 10 verschiedene Mutationstypen: Textfehler, fehlende Elemente, falsche Zustände, Layout-Brüche, falsche Daten, fehlende Bilder, falsche Redirects, subtile Farbänderungen, Reordering und Timing-Probleme.
Zum Vergleich: Ein Playwright-Test hat technisch 100 Prozent Accuracy — aber nur für exakt das, was er testet. Alles außerhalb seiner Assertions ist unsichtbar. Aletiq hat eine niedrigere Punkt-Accuracy, deckt aber ein breiteres Verhaltens-Spektrum ab, weil es Verhalten bewertet, nicht einzelne Selektoren.
Für welche Projekte eignet sich Aletiq besonders?
Aletiq löst ein spezifisches Problem: Verification in schnell ändernden Codebases. Drei Projekttypen profitieren am meisten:
1. AI-generierte Codebases
Wenn du Claude Code, Cursor, Copilot oder andere AI-Agents für Feature-Entwicklung nutzt, ändert sich deine Codebase schneller als du Tests schreiben kannst. Playwright-Tests veralten innerhalb von Stunden. Aletiq-Intents bleiben stabil, weil sie an Verhalten gekoppelt sind.
2. Solo-Entwickler und kleine Teams
Wer alleine oder zu zweit entwickelt, hat keine Kapazität für eine umfangreiche Playwright-Suite mit Page Objects, Fixtures und CI-Pipeline. aletiq verify "..." braucht 5 Sekunden statt 5 Stunden Setup.
3. Projekte mit schneller Iteration
MVPs, Prototypen, Startups in der Early Stage — überall wo sich die UI wöchentlich ändert, ist eine selector-basierte Test-Suite mehr Last als Hilfe. Aletiq wächst mit deinem Projekt, ohne Maintenance-Schulden aufzubauen.
4. CI/CD-Gates für kritische Flows
Aletiq lässt sich als Gate in GitHub Actions oder GitLab CI einbinden. Jede PR wird gegen deine definierten Intents verifiziert — Merge wird blockiert, wenn ein kritischer Flow wie Checkout oder Signup nicht mehr funktioniert.
Aletiq ist MCP-nativ und funktioniert mit allen gängigen AI-Coding-Tools: Claude Code, Cursor, Codex, Gemini, GitHub Copilot, Windsurf, Aider, Continue, Cline und Devin.
Wann ist Playwright trotzdem die bessere Wahl?
Playwright ist ein exzellentes Tool — und in bestimmten Szenarien die eindeutig bessere Wahl als Aletiq. Ehrliche Einschätzung:
- Unit-artige UI-Tests — Wenn du präzise testen willst, ob ein spezifischer State in einer spezifischen Komponente den korrekten Output produziert (z.B. „Dropdown rendert exakt 5 Optionen bei diesem Dataset"), ist Playwright mit seiner Assertion-Bibliothek präziser als Intent-Verification.
- Performance-Testing — Playwright kann Ladezeiten messen, Network-Requests intercepten und Performance-Metriken sammeln. Aletiq verifiziert Verhalten, nicht Performance.
- Große Teams mit bestehender Test-Infrastruktur — Wenn du 500+ Playwright-Tests hast, ein QA-Team das sie wartet und eine CI-Pipeline die zuverlässig läuft, ist ein Wechsel zu Aletiq kein Quick Win. Die bestehende Infrastruktur hat bereits ihren größten Kostenpunkt (Setup) hinter sich.
- Stabile, langlebige Codebases — Wenn sich deine UI einmal im Quartal ändert und nicht wöchentlich, ist Test-Maintenance kein großes Problem. Playwright-Tests funktionieren gut in Codebases mit niedriger Änderungsrate.
- Regulatorische Anforderungen an Test-Dokumentation — Wenn du für Compliance-Zwecke nachweisen musst, dass spezifische technische Bedingungen geprüft werden (nicht nur Verhalten), braucht du deterministische, code-basierte Tests.
Die beste Kombination für viele Teams: Playwright für die kritischen, stabilen Kernflows (Login, Checkout, Payment) und Aletiq für alles, was sich häufig ändert (Landing Pages, Feature-Bereiche, AI-generierte UIs).
Wie starte ich mit Aletiq?
Ein Befehl — kein Setup, keine Konfiguration, keine Test-Dateien:
aletiq verify "The main CTA should navigate to the pricing page" --url https://myapp.comIn 4,5 Sekunden bekommst du ein Verdict: PASS, UNCLEAR oder FAIL — mit Begründung, Screenshots und Evidenz.
Drei Wege, Aletiq in deinen Workflow zu integrieren:
- Dev Loop (CLI) — Direkt im Terminal, während du entwickelst. Dein AI-Agent kann
aletiq verifynach jedem Refactoring aufrufen und sicherstellen, dass nichts kaputt ist. - MCP-Integration — Aletiq ist MCP-nativ. Claude Code, Cursor und andere AI-Agents können Verification direkt in ihren Workflow einbinden — ohne dass du manuell verifizieren musst.
- CI Gate — Als Schritt in GitHub Actions oder GitLab CI. PRs werden erst gemergt, wenn alle definierten Intents PASS sind.
Pricing:
| Tier | Preis | Verifications/Monat | Features |
|---|---|---|---|
| Free | $0 | 50 | L0-L3, Single Project, MCP |
| Pro | $99/Monat | 500 | Alle Levels (L0-L5), Unlimited Projects, CI/CD, Knowledge Graph |
| Team | $299/Monat | 2.000 | Alles in Pro + Team Workspace, SSO, RBAC, SLA |
Der Free Tier reicht für Solo-Projekte und zum Ausprobieren. 50 Verifications pro Monat bedeuten: Du kannst die wichtigsten 10 Intents deiner App 5-mal im Monat verifizieren — genug für wöchentliche Releases.
Probiere Aletiq jetzt aus: aletiq verify auf deinem Projekt — in 5 Sekunden weißt du, ob deine Software noch das tut, was sie soll.